Back to (Prompt) Basics
After the last post, where I gave Semantic Kernel a try, I gave the bigger question some more thought. Do I really need to use such a framework now, for my personal explorations? To not bury the lede, in my case: no, I don’t think I really need an AI app framework right now, be it Semantic Kernel, or LangChain, etc. The basic AI building blocks (e.g., calling LLMs, extracting structured data from PDFs) should be more than enough for me right now.
Don’t get me wrong, it’s useful to give frameworks a try, just to learn what they are and a bit of what they can do, to remove some of the mystery. Same thing with books. You might think a book is interesting based on the title, cover, some quotes or recommendations, what people or articles are saying about it online, etc., but you won’t really know until you start reading the book, inspecting the table of contents, etc. That’s why I like it that Kindle allows you download the first pages of eBooks for free; this is a great way to validate if the book is worth reading at all, right now, etc.
I’m sure I’ll keep kicking the tires on things like Semantic Kernel, LangChain, etc, but the more important thing for me to do right now is to identify, prioritize, and explore my own AI-relevant problems or challenges, with a heavy emphasis on things that can be tried simply and directly.
In other words:
- I should be organizing my efforts by personal need, not by framework (i.e., organize by nails, not hammers)
- But I should balance that with operating in a bottom-up, simple-to-complex fashion, in terms of what I can solve for the least effort (i.e., bias for simple-hammer tasks)
Why? Because I don’t have a ton of time outside of work and family, so I need to prioritize my time in terms of quick ROI, but still try to tackle interesting or useful problems.
In my case, a very useful AI-relevant task is extracting structured data from PDFs. Think about it: if I can do this reliably, personal finance tasks become much easier. I can just use spreadsheets and not have to use Quicken. A big value of Quicken is their automatic download functionality. But if it’s easy for me to get the data out of statements (which I download anyways for posterity), then I just extract that data and append it to a spreadsheet.
I don’t know all the models that are good about PDF data extraction, but since I used to work at Google, I know Gemini is actually pretty good at this, it’s kinda cool.
Gemini has a nice starter page on PDF extraction here. I used Python as the sensible and simple choice for me. So I took the example code from the aforementioned page, tweaked it to my needs, and got this:
import os
import pathlib
import sys
import httpx
from google import genai
from google.genai import types
GEMINI_API_KEY = os.environ['GEMINI_API_KEY']
if not GEMINI_API_KEY:
print("please set env var GEMINI_API_KEY. Exiting...")
sys.exit(1)
pdf_path_str = # ... path to an Amazon invoice PDF
pdf_path = pathlib.Path(pdf_path_str)
prompt="""I need you to extract information from a PDF for me.
I am sending you a PDF of an Amazon.com order invoice. In the invoice is a section called
"Items Ordered". In this section is one or more rows. Each row describes one of the items ordered.
From each row, I want you extract the following information:
* The description of the item ordered
* The price of the item ordered
Ignore the lines that start with:
* Condition:
* Sold by:
* Supplied by:
I don't care about that information. I just want the item description and price, as I explained earlier.
Return the information in a 2 column TSV format. Do not use a header row. The first column should
be the description, and the second column the price. Do not wrap long lines. Each item should be
1 row in the output.
Please do this correctly. Thank you.
"""
client = genai.Client(api_key=GEMINI_API_KEY)
response = client.models.generate_content(
model = 'gemini-2.0-flash',
contents = [
types.Part.from_bytes(
data=pdf_path.read_bytes(),
mime_type="application/pdf"
),
prompt
]
)
print(response.text)And lo and behold, it worked on at least 1 PDF! (TBD how reliable it will be). Here is my input PDF:
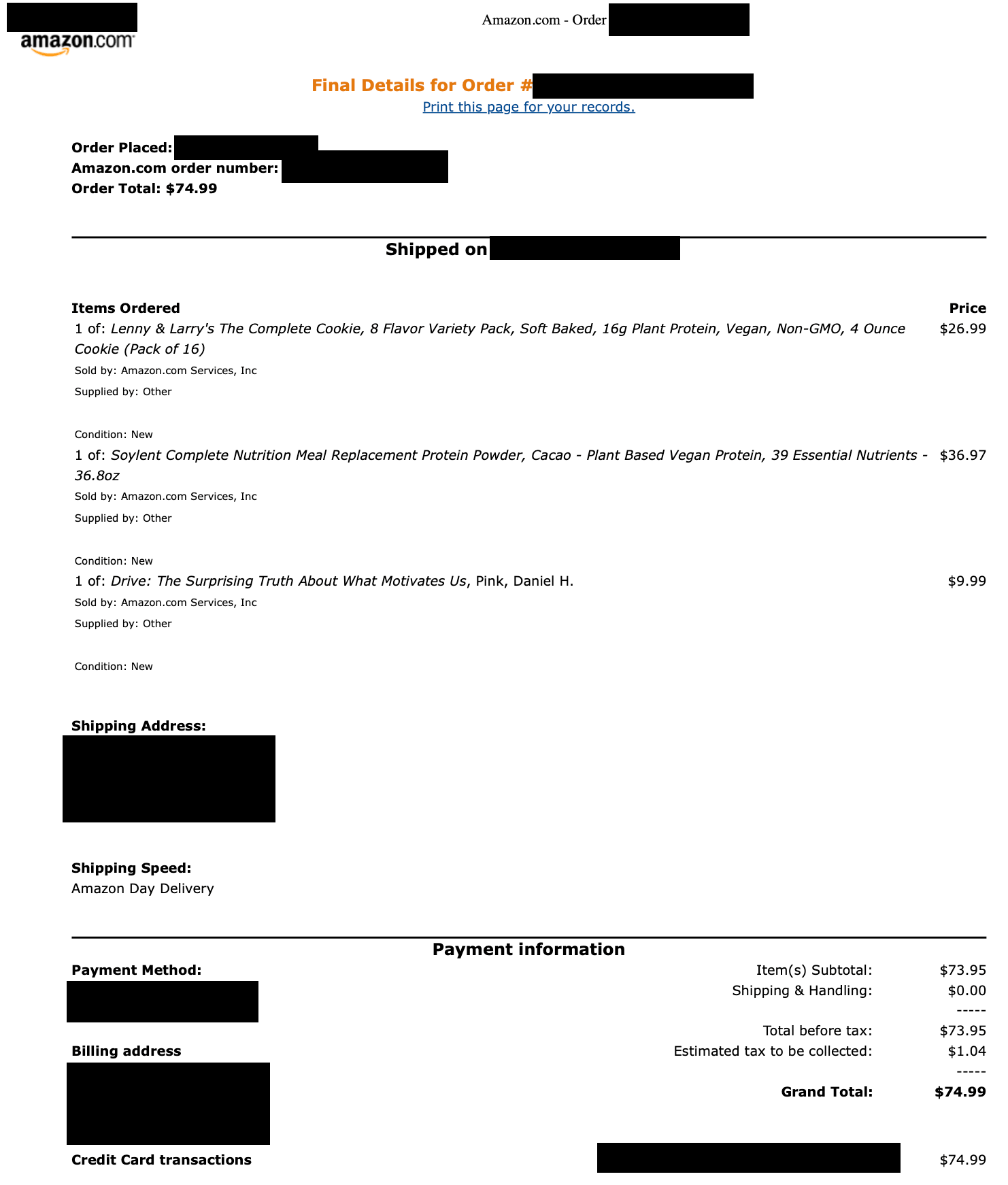
(I didn’t redact the PDF sent to Gemini. Rather, I just did this for the image posted here)
And the output was:
Lenny & Larry's The Complete Cookie, 8 Flavor Variety Pack, Soft Baked, 16g Plant Protein, Vegan, Non-GMO, 4 Ounce Cookie (Pack of 16) $26.99
Soylent Complete Nutrition Meal Replacement Protein Powder, Cacao - Plant Based Vegan Protein, 39 Essential Nutrients 36.8oz $36.97
Drive: The Surprising Truth About What Motivates Us, Pink, Daniel H. $9.99
The only thing I had to tweak was adding the requirement to not wrap lines. The first attempt had lines wrapped at an arbitrarily column, which wasn’t useful. It even got rid of the “1 of”, and TBD if I need it or not (most of my orders are for “1 of”). It mostly got the line wrapping right; it just lost a hyphen on the end of the first line of the Soylent item, which isn’t a big deal for my case.
Anyways, that’s it for now. Just wanted to share that, as it’s quite cool that it works without much effort. Next step would be to explore appending that data to a sheet, which is basically covered by the sample code here.